About Vulkan and Future of High Performance Computing
Towards a heterogeneous & parallel computing architecture
OpenCL and Vulkan in the future would probably become the same thing. [1][2]
To utilise the power of Vulkan (and OpenCL) we do not have to code it our own, espectially for the purpose of deep learning.
By the way, some framework utilise OpenGL (Compute Shader API) as well, a higher level API.
Mali-G series GPU supports OpenCL 2.0 full profile.
Good Reads for Mobile DL
Neural Network Inference on Mobile SoCs https://arxiv.org/pdf/1908.11450.pdf
A First Look at Deep Learning Apps on Smartphones https://arxiv.org/pdf/1812.05448.pdf
AI Benchmark: Running Deep Neural Networks on Android Smartphones https://arxiv.org/pdf/1810.01109.pdf
- good review of the SoCs (Hardware Acceleration, different SDKs)
Chips for Consideration
without NPUs
NXP
iMX6 or iMX8 - popular for general and multimedia usage.
with NPUs
Amlogic
Amlogic A331D (with NPU) (Khadas VIM3)
Amlogic S922X (ODROID-N2)
Their own SDK

No known popular usage.
RockChip
Popular chip used in hobbists and multimedia products. Contribute significantly to open source community.
RockChip is upgrading their product line this year 2020 with RK3588. their flagship RK3399 is getting dated. To be equipped with NPUs.
RK1808, RK1806 are supported by Baidu Paddle. Only single camera input is supported.
MediaTek(APU)
MT8168, MT8175 (Mali G52, with APU 0.3TOPS, 2 CSI camera interface)
- only chips available?
MediaTek NeuroPilot SDK (Andriod only)
Supported by Baidu Paddle using API conversion.
Newer series
MediaTek helio
- P60 280GMAC/s
- P90 APU 2.0 @ 1165GMAC/s
No available development boards
Kirin
Kirin970 and Kirin980 uses Cambricon Technologies. (supported by HiAI DDK(v100), but only Andriod?) Kirin 810 and 820 and Kirin 990 uses Da Vinci NPU
Da Vinci NPU is supported by Baidu Paddle using API conversion. No development board available.
HiSilicon
Hi3516A(V300) - NNIE 1.0 TOPS (ARM A7)
Hi3519A(V100) - NNIE 2.0 TOPS @ 2W (ARM A53) Taobao

Hi3559A(V100) - Dual NNIE@840MHz (much more powerful CPU, ARM A73 + A53) Taobao (huge size)


http://www.hisilicon.com/en/Products/ProductList/Camera
Custom SDK May not be easy to use.
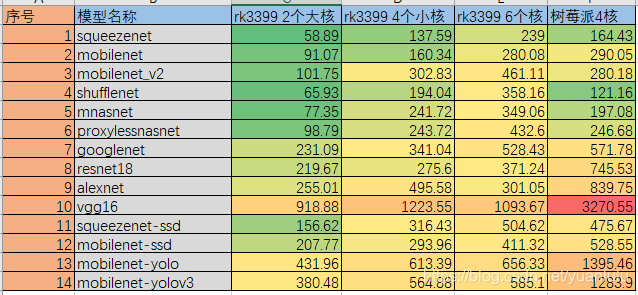
Benchmark Other Blog Yolov3 8fps, slightly better than TX1? Inferior than TX2.
Horizon Robotics
BOOTPRINT X2 96Boards ( Sunrise 2.0 AI edge processor - 4 TOPS@2W )

Uncertainty facing a start-up product
Bottomline
- Current Multimedia SoC are adding in NPUs quickly, but with custom SDKs mainly
- Start up SoC is still largely uncertain its sustainability
- Do no expect too much from the built-in NPU performance. More like a off-loading.
DL Framework Comparisons
overview of mobile DL framwork: https://easyai.tech/blog/10-mobil-deeplearning-frame/
嵌入式Linux平台部署AI神经网络模型Inference的方案 https://www.jianshu.com/p/d4425b65c6e6
Future of GPU-based High Performance Computing (NPU to replace GPU) https://zhuanlan.zhihu.com/p/114254288
Tensorflow Lite
Not Recommaned
Mainly focused on Andriod and iOS, so not so friendly for our Robotics use, less documentation and popularity.
Blog: TensorFlow Lite Now Faster with Mobile GPUs This blog shows that only Andriod and iOS are officially supported (basically what Google has in mind).
Note: the full version of Tensorflow could run on with custom compilation from source. GitHub No Official support, and it is probably CPU-only.
PyTorch
Not Possible: Requires CUDA as the sole option for dependencies.
Paddle-Lite by Baidu

Key Features
- Official support Mali GPU (OpenCL), Andreno GPU, Apple Metal GPU
- Official support Kirin NPU, MTK APU, RK NPU
- Future support includes Cambricon and Bitmain
- Available in both Lite and Full (CUDA) version, tested on Jetson TX2
- Support Yolov3 since version 2.0 (launched in late 2019)
- 5K GitHub Stars, QQ support group 696965088
- Tons of improments and tricks and tools like x2paddle
Key Drawbacks
- Still transiting older versions of Paddle-Mobile to the rebranded Paddle-Lite
- Reported that documentation is not friendly, for starting. (Refering to version 1, not sure if version 2 improved) Zhihu, Developer Reply
Paddle-Lite benchmark, Paddle-Lite Demo, Release Blog
Bottom Line
- Interesting framework to test Kirin NPU (Kirin 970 1.92TFLOPs) and RK NPU (RK1808, RK1806,not currently RK3399Pro) performance. However, currently those chips are not miniturisable.
- Hi35xx chips (Hi3559A NPU: Dual core NNIE; Hi3516A, 2TOPS) not supported, probably need to use NNIE instead (takes in caffe format)
- Still good to use it for complete GPU support
NCNN by Tencent

Key Features
- Design to be light-weight (library <1MB)
- Optimised memory access, written all in C++
- ARM NEON Assembly optimisation, ARM big.LITTLE CPU optimisation
- Utilise VulKan API, for GPU acceleration
- Support import from caffe/pytorch/mxnet/onnx
- QQ Support Group: 637093648
Key Drawbacks
- Focused on Android platform, many users. But on Linux platform untested.
- Compilation instruction includes Hisilicon (Hi35xx) and Arm64, but not sure if GPU acceleration and NPU acceleration is enabled
Tencent NCNN claims that their CPU optimisation is quite good (fastest among open-sourced ones), might even outperform the built-in GPU
Bottomline
- Claimes to be fast, with good CPU optimisation
- could be a good GPU benchmark as well (using Vulkan instead of OpenCL)
MaliG72 looking good with ncnn
MNN by Alibaba

Key Features
- Claimed CPU assembly optimisation
- Android: OpenCL, Vulkan, OpenGL support (very comprehensive!)
- Appear to support ordinary Linux too, from doc
- Lightweight
- Support Tensorflow, Tensorflow Lite, Caffe and ONNX (PyTorch/MXNet)
- Feels to be research oriented
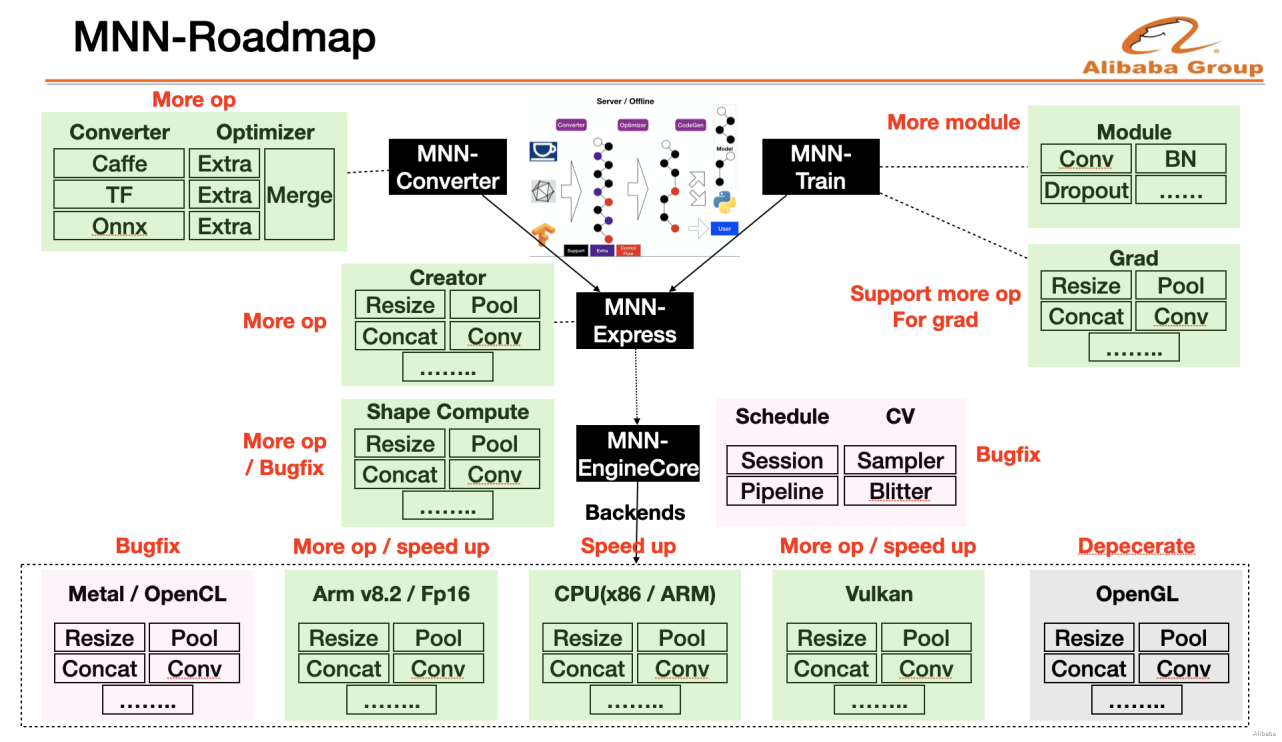
Key Drawbacks
- Just released as open source (2019?) (semi-automated search architecture for better mobile deployment)
- The features looks too good to be ture. But lets hope for the best.
Bottomline
- The paper is worth reading
- A new option with good potential
MXNet by Amazon
https://github.com/apache/incubator-mxnet
![]()
Key Features
- Used in Universities to teach deep learning classes (Famous book: dive into deep learning)
- Great documentation, looks easy to get started with Python
- Integration with TVM
Key Drawbacks
- seems no support for ARM GPU or NPU
- Comparison with tvm, from tvm blog back in 2018. Results not good for MXNet.
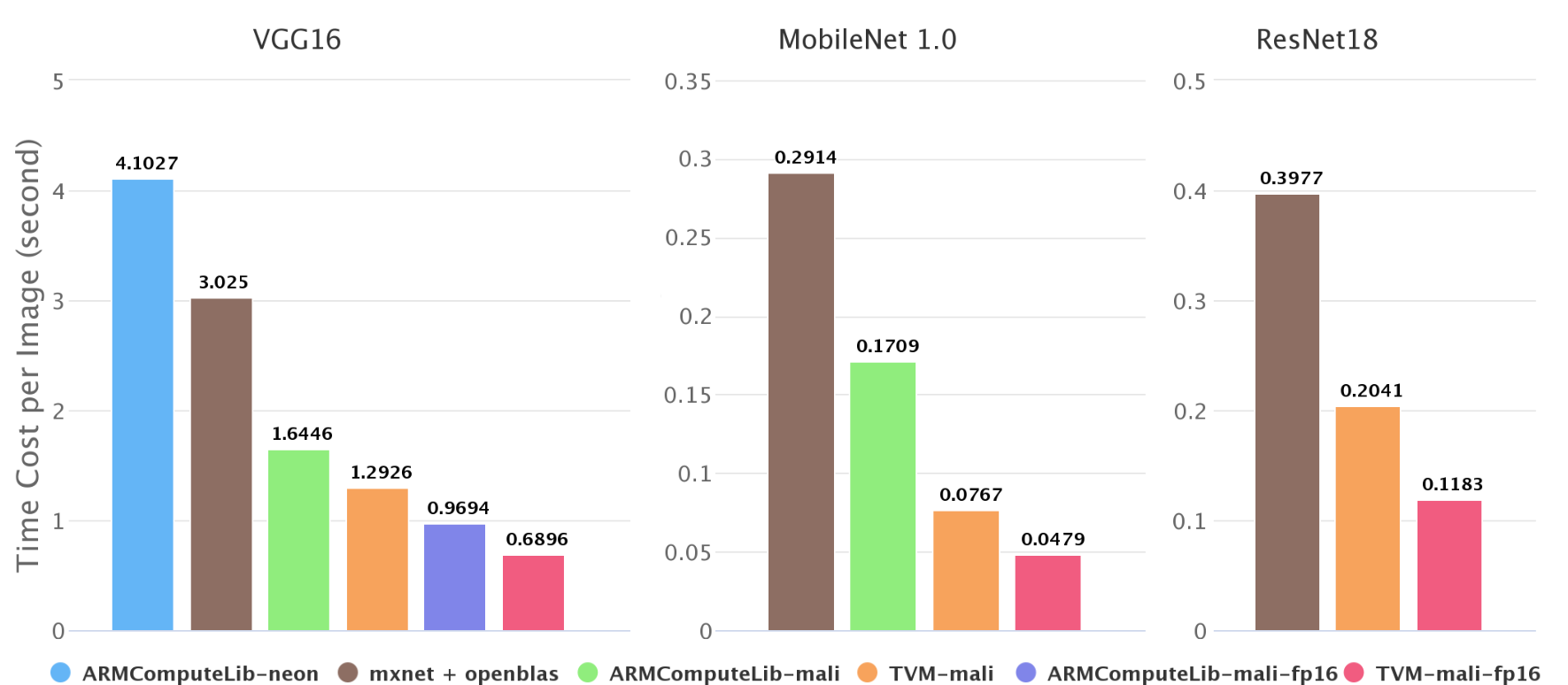
Bottomline
- Not for us. It is for bigger machines, cluster of machines.
Mace by Xiaomi
Not recommanded.
- Does not support CUDA
- Does not support popular Raspberry Pi
- Hard to find non-Andriod documentation.
- Xiaomi's strength is in Quadcomm CPUs
- Not as a big community using it
Tengine by OPEN AI Lab (Supported by ARM)
https://github.com/OAID/Tengine
Not recommended. only ARM CPU acceleration? But claim to be fast?
ARM NN
Not recommended. Should not go here, again, platform dependent!
It should be based on ARM Compute Library.
SenseTime Parrots (PPL)
Closed source, but claim to have the best performance among the commercial solutions.
TVM (An Aggressive Step: Auto Tuning)
Key Features
- Support ARM GPU (uda, opencl or vulkan backend)
- Could add custom accelerator support through VTA (e.g. FPGA)
- Machine Learning the best combination to utilise the heterogeneous hardware
Key Drawbacks
- Might be too many things varying at the same time, hard to debug?
Integrating TVM into PyTorch https://tvm.apache.org/2019/05/30/pytorch-frontend
云天励飞基于TVM https://zhuanlan.zhihu.com/p/91826247 https://www.intellif.com/int/product/list15.html
Optimizing Mobile Deep Learning on ARM GPU with TVM https://tvm.apache.org/2018/01/16/opt-mali-gpu
A Unified Optimization Approach for CNN Model Inference on Integrated GPUs https://arxiv.org/pdf/1907.02154.pdf